concerning CUDA 3.x on Darwin
as the first of several CUDA articles.
The following are some brief introductory notes on dumping PTX kernels from modern CUDA applications, as well as techniques for embedding them within new applications. One or two copies of every shader are stored as ASCII strings within each CUDA executable by default. With a little ingenuity, the contents of this article and a decent machine with a G80 card should provide a decent start in reverse engineering general-purpose GPU applications.
Nvidia's CUDA framework for GPU computing uses a portable meta-assembly language, PTX (ptx_isa_2.0.pdf), to facilitate translation between multiple GPU devices. In this manner, they can escape the backward compatibility issues that hold most modern CPU architectures to a single instruction set. PTX vaguely resembled the underlying machine code, but it lacks features which would tie it to any particular GPU. In this brief article, I present a trivial method for extracting PTX assembly from CUDA applications, as well as some pointers for merging that code into new applications.
Dumping
The screenshot below shows a fragment of libcublas.dylib from CUDA 3.0 in Snow Leopard being edited in Emacs. Following the dozens of assembler directives are individual VM opcodes. (This contains Basic Linear Algebra Subprograms. As this comes from Fortran, not C, the code is a bit weird.) By default, CUDA will compile inline code in a language similar to C into PTX assembly, then include the PTX assembly string verbatim into the resulting executable or library. User comments are not preserved, but compiler comments are introduced and names are unaltered. Except where hand-written, the compiler will always be nvopencc.

The nvopencc compiler has a number of quirks when writing PTX:
- Every line that is not a label is tabbed in at least once.
- The first directive is .version, the second is .target.
- Registers are declared in groups.
- Names are preserved, with C++ mangling.
Further,
- Every PTX script ends with a null (0x00) byte.
- While they can be big, no PTX script is larger than two megabytes.
- PTX scripts come in pairs, one for sm_20 and another for sm_10.
To dump the PTX code from a binary, Mach-O executable, just scan the input for long strings, printing everything starting with "\t.version". In my own setup, I have an ugly C program that prints these, passing them off to the unix split command for separation into multiple PTX files.
The 312 PTX scripts from CUBLAS are mostly small, with only nine of them having source in excess of a megabyte but none being larger than two megabytes. Thus, you'll need a rather long string buffer. Additionally, it is handy to purge the buffer when no fragment of a PTX executable is found and whenever a null byte is encountered. You can find the PTX from the vectorAdd example at http://pastebin.com/nqKqKhNc.
Applications can be compiled without PTX inclusion, using machine-language CUBIN files instead. This has the disadvantage of not being forward-compatible, and thanks to Wladimir J. van der Laan's Decuda project, it isn't much more difficult to read.
To try this out yourself, first build a dumping script based upon the CUDA examples and libraries. Once you have that, try downloading a few of the more advanced demos. The Nvidia Graphics Plus demos might be a good target, as would any game advertising CUDA support.
PTX JIT
Having dumped a PTX script, it is handy to link it back into an existing project. For this, you will want to use the matrixMulDynlinkJIT or ptxjit examples that come with the CUDA development kit. These projects use the cuModuleLoadDataEx() method to link a PTX script from a string, then cuModuleGetFunction() to grab a CUfunction pointer to any function.
Conveniently, the PTX scripts include symbol names, but as with any complex compiler, these have been somewhat mangled. In the addVector example, the entry point hask been mangled to _Z6VecAddPKfS0_Pfi for both sm_10 and sm_20. It is this function name, and not the simpler VecAdd, that must be passed to cuModuleGetFunction().
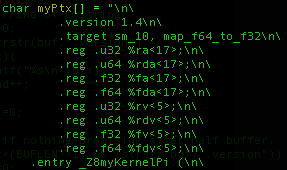
This is the code that the ptxjit example uses to load a kernel named _Z8myKernelPi kernel contained within the myPtx[] character array. Looking at the string itself, which is defined within ptxjit.h, it can be seen that the code was rather hastily dumped by a method similar to the one I describe above.

Caveats
GPU programming is sufficiently confusing when source code is available that the lifting of code oughtn't be a concern. Generally only small fragments are executed within the GPU, with the majority of development time being spent debugging those fragments and twisting them for different physical optimizations.
Daniel Reynaud's talk on GPU Powered Malware at Ruxcon 2008 proposed that GPU programs might be useful for malware URL generation. It goes without saying that sophisticated malware will do better than to include an unencoded ASCII string. Pre-assembled bytecode can be provided directly to the card, avoiding the inclusion of a PTX string. While some of Reynaud's points are less relevant now that CUDA has debugging and bytecode emulation, the core of his argument that GPU packers will become important is still valid. For starters, it is possible use a pegged memory segment to have GPU code rewrite host X86 code on the fly without a context switch!
Expect some follow-up articles on the neighborly things that can be done once your hands are inside the beast that is CUDA.

40 comments:
You might enjoy a few of my projects:
CUBAR -- tools for CUBAR microarchitecture and security exploration: http://dank.qemfd.net/dankwiki/index.php/CUBAR
libcudest -- reverse engineering of libcuda.so with the goal of an open implementation: http://dank.qemfd.net/dankwiki/index.php/Libcudest
and then i've got some general thoughts here. good article; i look forward to some more!
I am using AVG security for a few years, and I would recommend this antivirus to all you.
QUANTUM BINARY SIGNALS
Professional trading signals sent to your cell phone every day.
Start following our trades today and profit up to 270% per day.
Hello There. I found your weblog using msn. This is an extremely well written article. I will be sure to bookmark it and come back to learn more of your useful information. Thanks for the post. I will certainly comeback.
Shop Drawings Preparation
Shop Drawings Preparation in USA
Look at this https://edit-proofread.com/blog/how-to-write-complaint-letter if you want to change some thing on your project!
Are you looking to buy the Best Custom Essay Paper from the best writers? When given assignments, many students look for Top-Ranked Essay Writing Service and through a basic web search, you can find many online companies offering help with Best Custom Essay Ever.
I am really impress with you for the selecting of new and unique topic and also well written article on it. Thanks for sharing with us.
online knowledge portal
Thank you for sharing with us! Good luck!
vivi winkler
In need of professional law assignment writing service in the UK turnout to Assignments Planet for all your assignment and essay works.
Thanks for sharing this. This is definitely going to help a lot others.
Is anyone in Dubai finding a good gym to join? Visit our site now to become a member.
Visit Now: MYFITAPE
If You Are Looking For Best Online Pharmacy That Can Provide You Best Medications. Than, We Are Here To Provide You The Best Medications. Just Click On Links Below And Order Now.
OTC ADHD Pills
OTC Anti-Anxiety Pills
Erectile Dysfunction Pills Online
OTC Muscle-Relaxant Pills
OTC Malaria Pills
Thank you so much for sharing a such wonderful piece of information that really help for people, Keep going on great work appreciate your effort,
Visit my website SunCoastLaw
Hi,
Thanks for sharing such wonderful information that is really helpful for people to keep going on. If anyone from Dubai and searching for Dubai trip than visit our website dubaitraveltourism
I am really Thankful to you for The brief introductory notes on dumping PTX kernels from modern CUDA applications and as well as techniques for embedding them within new applications. Now its time to availshop fittersfor more details.
If you're struggling with extracting PTX code from CUDA programs, take my class help service provide you with the necessary skills and knowledge to perform this task efficiently. You'll learn about the underlying architecture, instructions, and techniques to extract PTX code and optimize it for specific use cases.
CUDA PTX extraction is a valuable process in GPU programming that involves extracting PTX (Parallel Thread Execution) code from CUDA source code. This step is essential for optimizing and fine-tuning GPU performance. If you want to deepen your understanding of CUDA PTX extraction and enhance your programming skills, consider seeking Online Class Help can provide you with valuable guidance and resources to master this technique.
Your blogs are really good and interesting. It is very great and informative bankruptcy lawyers in virginia beach. One or two copies of every shader are stored as ASCII strings within each CUDA executable by default. With a little ingenuity, the contents of this article and a decent machine with a G80 card should provide a decent start in reverse engineering general-purpose GPU applications. I got a lots of useful information in your blog. Keeps sharing more useful blogs..
Great article! I found your insights really informative. I would like to share information about the company. Introducing our cutting-edge Grocery App Development Company, where innovation meets convenience! Elevate your grocery shopping experience with our custom-built mobile applications that seamlessly blend technology and user-friendly interfaces.
Unleash your professional prowess with our executive CV writing services. Our seasoned writers specialize in highlighting your executive experience and creating a powerful resume that resonates with recruiters. Secure your next career move by entrusting our team to articulate your leadership achievements through our executive CV writing services.
Osh University, recognized as the international higher school of medicine , is a leading institution for medical education. With a global outlook, it attracts aspiring medical professionals from various countries.
Shalamar Hospital, home to the best neurosurgeon in Pakistan , provides a commitment to excellence in neurological care, giving patients the highest level of expertise and treatment.
B.B Code
[url=https://www.kafastourism.com/]dubai city tour[/url]
Code type.
Mark Down
[dubai city tour](https://www.kafastourism.com/)
wiki code
[https://www.kafastourism.com/ dubai city tour]
Is this information useful?
Jewelgalore is your premier destination for online Pakistani jewelry . Explore their exquisite collection and adorn yourself with intricately designed pieces that reflect the cultural richness and artistry of Pakistan.
The CUDA PTX Extraction article offers a comprehensive guide for developers to extract PTX code from CUDA programming. It provides step-by-step instructions, making the process accessible for both beginners and experienced developers. Practical examples enhance understanding of PTX extraction and its applications in CUDA development. This resource is an invaluable reference for those delving into GPU programming, offering a comprehensive overview of PTX extraction techniques. Its clear organization and concise explanations make it a standout resource for those seeking a deeper understanding.
New Jersey Domestic Violence Attorney Cherry Hill
wonderful information available in this blog regarding
female to male spa near me
CUDA PTX extraction is essential for optimizing GPU performance in various applications, from AI to complex automotive simulations. By extracting PTX (Parallel Thread Execution) code, developers can gain a deeper understanding of GPU functionality and make precise performance improvements, especially beneficial in high-demand industries like automotive engineering. For insights and guides on the latest in automotive technology, check out fleetsworld for up-to-date information.
At our best Lasik Austin clinic, we prioritize patient satisfaction and safety above all else. We adhere to strict medical guidelines and protocols to ensure that each procedure is performed with the highest standards of quality and precision. Our commitment to excellence has earned us a reputation as a trusted provider of Lasik surgery in the Austin area.
Whether you are seeking to reduce your dependence on glasses or contact lenses, or simply want to improve your overall quality of life with clearer vision, our clinic is here to help you achieve your goals. Contact us today to schedule a consultation and take the first step towards better vision.
This paper provides good insights into reverse engineering CUDA apps and programming with PTX kernels. The technical analysis is straightforward and informative. For students juggling tricky tasks such as this, it's usually wise to get hire someone to do my exam while concentrating on experiential learning and a head start.
Post a Comment