concerning CUDA 3.x on Darwin
as the first of several CUDA articles.
The following are some brief introductory notes on dumping PTX kernels from modern CUDA applications, as well as techniques for embedding them within new applications. One or two copies of every shader are stored as ASCII strings within each CUDA executable by default. With a little ingenuity, the contents of this article and a decent machine with a G80 card should provide a decent start in reverse engineering general-purpose GPU applications.
Nvidia's CUDA framework for GPU computing uses a portable meta-assembly language, PTX (ptx_isa_2.0.pdf), to facilitate translation between multiple GPU devices. In this manner, they can escape the backward compatibility issues that hold most modern CPU architectures to a single instruction set. PTX vaguely resembled the underlying machine code, but it lacks features which would tie it to any particular GPU. In this brief article, I present a trivial method for extracting PTX assembly from CUDA applications, as well as some pointers for merging that code into new applications.
Dumping
The screenshot below shows a fragment of libcublas.dylib from CUDA 3.0 in Snow Leopard being edited in Emacs. Following the dozens of assembler directives are individual VM opcodes. (This contains Basic Linear Algebra Subprograms. As this comes from Fortran, not C, the code is a bit weird.) By default, CUDA will compile inline code in a language similar to C into PTX assembly, then include the PTX assembly string verbatim into the resulting executable or library. User comments are not preserved, but compiler comments are introduced and names are unaltered. Except where hand-written, the compiler will always be nvopencc.

The nvopencc compiler has a number of quirks when writing PTX:
- Every line that is not a label is tabbed in at least once.
- The first directive is .version, the second is .target.
- Registers are declared in groups.
- Names are preserved, with C++ mangling.
Further,
- Every PTX script ends with a null (0x00) byte.
- While they can be big, no PTX script is larger than two megabytes.
- PTX scripts come in pairs, one for sm_20 and another for sm_10.
To dump the PTX code from a binary, Mach-O executable, just scan the input for long strings, printing everything starting with "\t.version". In my own setup, I have an ugly C program that prints these, passing them off to the unix split command for separation into multiple PTX files.
The 312 PTX scripts from CUBLAS are mostly small, with only nine of them having source in excess of a megabyte but none being larger than two megabytes. Thus, you'll need a rather long string buffer. Additionally, it is handy to purge the buffer when no fragment of a PTX executable is found and whenever a null byte is encountered. You can find the PTX from the vectorAdd example at http://pastebin.com/nqKqKhNc.
Applications can be compiled without PTX inclusion, using machine-language CUBIN files instead. This has the disadvantage of not being forward-compatible, and thanks to Wladimir J. van der Laan's Decuda project, it isn't much more difficult to read.
To try this out yourself, first build a dumping script based upon the CUDA examples and libraries. Once you have that, try downloading a few of the more advanced demos. The Nvidia Graphics Plus demos might be a good target, as would any game advertising CUDA support.
PTX JIT
Having dumped a PTX script, it is handy to link it back into an existing project. For this, you will want to use the matrixMulDynlinkJIT or ptxjit examples that come with the CUDA development kit. These projects use the cuModuleLoadDataEx() method to link a PTX script from a string, then cuModuleGetFunction() to grab a CUfunction pointer to any function.
Conveniently, the PTX scripts include symbol names, but as with any complex compiler, these have been somewhat mangled. In the addVector example, the entry point hask been mangled to _Z6VecAddPKfS0_Pfi for both sm_10 and sm_20. It is this function name, and not the simpler VecAdd, that must be passed to cuModuleGetFunction().
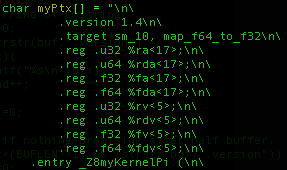
This is the code that the ptxjit example uses to load a kernel named _Z8myKernelPi kernel contained within the myPtx[] character array. Looking at the string itself, which is defined within ptxjit.h, it can be seen that the code was rather hastily dumped by a method similar to the one I describe above.

Caveats
GPU programming is sufficiently confusing when source code is available that the lifting of code oughtn't be a concern. Generally only small fragments are executed within the GPU, with the majority of development time being spent debugging those fragments and twisting them for different physical optimizations.
Daniel Reynaud's talk on GPU Powered Malware at Ruxcon 2008 proposed that GPU programs might be useful for malware URL generation. It goes without saying that sophisticated malware will do better than to include an unencoded ASCII string. Pre-assembled bytecode can be provided directly to the card, avoiding the inclusion of a PTX string. While some of Reynaud's points are less relevant now that CUDA has debugging and bytecode emulation, the core of his argument that GPU packers will become important is still valid. For starters, it is possible use a pegged memory segment to have GPU code rewrite host X86 code on the fly without a context switch!
Expect some follow-up articles on the neighborly things that can be done once your hands are inside the beast that is CUDA.
